

Dopo il report sui progressi raggiunti dall’emulatore Yuzu negli ultimi due mesi, il team ha rilasciato la tanto attesa Buffer Cache Rewrite in Early Access. Questa imponente impresa non solo migliora le prestazioni di Yuzu, ma ne semplifica anche lo sviluppo.
Affinché la GPU possa eseguire correttamente il rendering di qualsiasi cosa all’interno della programmazione grafica, questa necessita di alcuni dati, come ad esempio la posizione, il colore, e quant’altro.
Di solito, questi dati vengono forniti dall’applicazione. Ma quando sono presenti applicazioni di grandi dimensioni che trattano comunque dei grandi volumi di dati, diventa sempre più difficile riuscire a fornire costantemente i dati alla GPU e far eseguire il rendering, per porre rimedio a questo problema viene fatto uso del buffer cache.
Gli oggetti di tipo buffer sono oggetti di memoria che archiviano i dati di rendering nella memoria della GPU, aumentando così in modo significativo la riusabilità.
Esistono vari tipi di binding, comunemente indicati come tipi di buffer, come Index Buffer, Vertex Buffer e Uniform Buffer (tra gli altri). Ciò migliora le prestazioni di rendering perché i dati ora sono prontamente disponibili per essere utilizzati dalla GPU.
Buffer Cache di yuzu
L’emulatore Yuzu inizialmente ereditò un buffer di flusso, originariamente implementato per l’emulatore Citra dal developer degasus. Un buffer di flusso funziona in un ciclo di modifica/utilizzo, il che significa che aggiorna frequentemente l’oggetto buffer e lo lega a quella regione.
Rodrigo e Blinkhawk hanno successivamente implementato la cache del buffer esistente per lavorare insieme al buffer del flusso.
Non c’era niente di sbagliato in questo, i buffer di flusso difatti si sono da sempre dimostrati più veloci per caricare i dati sulla GPU. Ma quando Rodrigo ha profilato Yuzu, la gestione della cache e le copie di caricamento erano qualcosa che continuava a comparire lentamente.
[stextbox id=’info’]Nota: Nell’ingegneria del software, la profilazione (“profilazione del programma”, “profilazione del software”) è una forma di analisi dinamica del programma che misura, ad esempio, lo spazio (memoria) o la complessità temporale di un programma, l’uso di istruzioni particolari o la frequenza e la durata delle chiamate di funzione.[/stextbox]
Più comunemente, le informazioni di profilazione servono per aiutare l’ottimizzazione del programma. Il problema sta nel fatto che i giochi non sono esattamente dati in streaming tutto il tempo.
Pertanto, l’utilizzo di caricamenti immediati (su OpenGL) e una memorizzazione nella cache più rapida ha prodotto prestazioni migliori rispetto a un buffer di flusso e alla memorizzazione nella cache di grandi risorse, almeno per Nvidia.
Il nuovo Buffer Cache ha notevolmente migliorato il monitoraggio dei vari buffer che si memorizzano nella cache. Nella nuova implementazione, quando i buffer vengono creati nella memoria, vengono allineati forzatamente alle pagine 4K (4096 byte – a partire da zero).
Per sapere in modo efficiente quale buffer esiste, e su quale indirizzo, la cache utilizza un array piatto largo di 32 MiB per tradurre dalla pagina della CPU corrente in cui esiste il buffer a quale buffer risiede al suo interno.
ad esempio, se l’indirizzo è 4096 o 7000, quella è la pagina 1 e se è 8192, quella è la pagina 2. Così, il nuovo Buffer Cache può tracciare quali pagine di un buffer sono state modificate in base alla pagina invece di essere uno stato binario.
Immagina se un buffer ha una dimensione di 524288 byte e un gioco modifica solo 1 byte del buffer. Poiché i buffer ora sono allineati a 4096 byte come accennato in precedenza, solo quei 4096 byte vengono caricati sulla GPU.
La stessa cosa accade quando la GPU tenta di aggiornare la cache con i dati modificati dalla CPU. Questo rilevamento viene eseguito utilizzando array di bit nei buffer.
Ogni valore rappresenta lo stato della pagina – 1 viene modificato, 0 è chiaro. Mantenere le cose in un array di bit ci consente di utilizzare operazioni bit efficienti come std::countr_zero e std::countr_one (C++ 20). Ciò si traduce in un minor numero di istruzioni che producono gli stessi risultati (molto più velocemente).
L’obiettivo principale di questo lavoro e sempre stato quello di migliorare le prestazioni dell’emulatore, ma da questa riscrittura sono derivati anche alcuni miglioramenti grafici.


Le esplosioni ai vertici non sono più un problema in OCTOPATH TRAVELLER


Il rendering dei caratteri ora funziona per tutti i fornitori di GPU in Animal Crossing: New Horizons
Gli oggetti rilasciati smettono di lampeggiare in Xenoblade Chronicles Definitive Edition
Detto questo, parliamo delle prestazioni. Ovviamente, le metriche varieranno notevolmente a seconda dell’hardware e dell’API in uso.
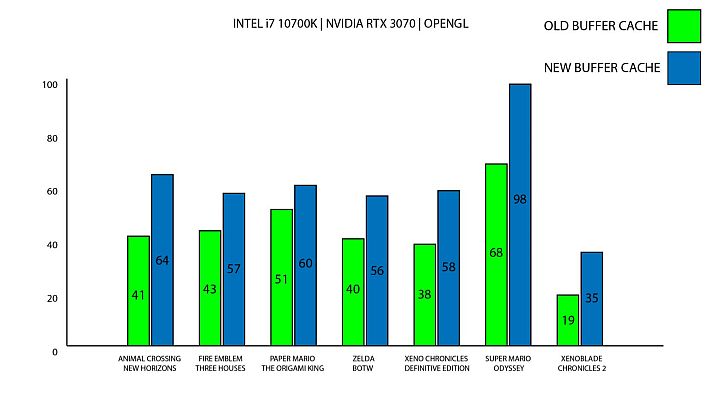
Ecco alcuni esempi misurati dopo un paio di run nelle aree più impegnative o comuni dei giochi elencati: Nvidia, in questo esempio rappresentato da un RTX3070, mostra prestazioni migliorate fino all’84% in OpenGL.
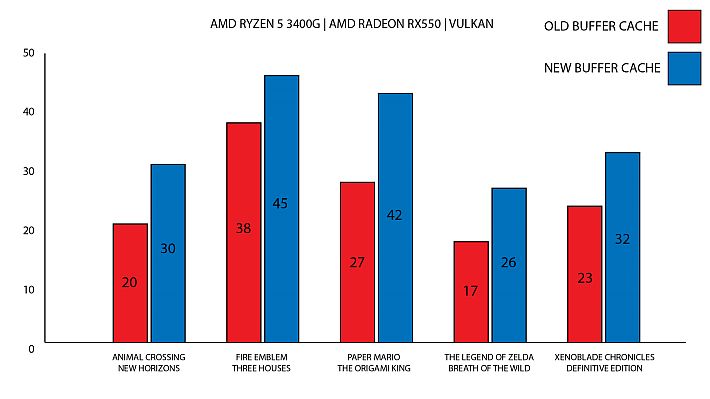
AMD invece, rappresentata da un piccolo RX550, mostra un miglioramento fino al 55% in Vulkan.
Per quanto riguarda Intel, sorge un problema non sorprendente. Tutti i colli di bottiglia dei prodotti attualmente rilasciati a causa di driver immaturi e semplicemente privi della potenza pura per l’emulazione Switch.
Ciò si traduce in miglioramenti delle prestazioni minimi o nulli con questa riscrittura. Si spera che questo possa essere risolto con miglioramenti futuri sia per yuzu che per i futuri driver e versioni hardware di Intel.
Come menzione speciale, le GPU integrate basate su AMD Vega mostrano un aumento fino al 223% in Paper Mario the Origami King, raggiungendo lo stesso livello di prestazioni delle schede dedicate di calibro molto superiore.
[stextbox id=’info’]Nota: Le funzionalità rilasciate in Early Access sono ancora in fase di elaborazione.[/stextbox]
Fonte: yuzu-emu.org









{kind=link}